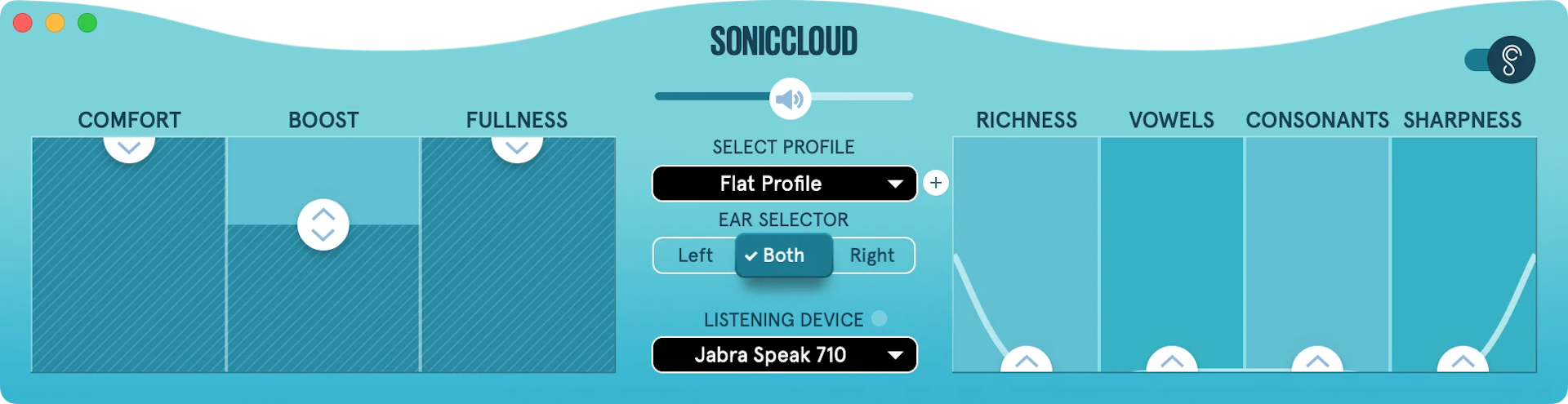
Hear how you want to hear with SonicCloud’s personalized
hearing software.
Sound so clear, it
gives you goosebumps

I want to live in the world of SonicCloud. It's magical.
- Michelle
SonicCloud is right for you if you have

Difficulty following conversations

Fatigue in calls or in video meetings

Difficulty hearing music and videos
Say Hello to SonicCloud Frisson
We're listening more than ever before
Experience what personalized audio can do for you while on video calls or streaming with our audiologist-developed digital solution.
Hear the Difference
Without SonicCloud
With SonicCloud

Recognition and Awards

Winner
Amazon Alexa Voice First

App of the Day
Apple Editorial Board
Finalist
World Changing Idea Award
Trusted by Audiologists

Dr. Robert Sweetow, PhD

SonicCloud is a transformative product that allows individuals to make changes for themselves that they cannot get with any other product on the market.
Used in World-Class Organizations